基于深度学习的机器翻译,简称深度机器翻译近两年来取得了惊人的进展,翻译的准确度综合评比已经超过传统的统计机器翻译,研究单位主要有蒙特利尔大学[1,2],斯坦福大学[3,4],清华大学[5,6],谷歌[3,7,8],微软[9]和百度[5,10],以及华为诺亚方舟实验室[11-13],竞争异常激烈。
最近谷歌发表论文[8],介绍了他们最新的研究成果,引起业界广泛关注,他们的系统主要采用了蒙特利尔大学、斯坦福大学、清华大学、以及华为诺亚方舟实验室的技术,以及一些工程上的优化,其最大特点是使用了大规模的训练数据。
我们在同一测试数据集上对谷歌、微软必应、及诺亚的系统做了评测(百度翻译因为直接记录了该测试集,无法直接比较),结果如下图所示。指标是业界标准 BLEU 点,一般来说人的 BLEU 值在50-70之间。
谷歌系统比诺亚系统高大概3个 BLEU 点。我们分析,这主要是因为谷歌系统集成了业界多种最新技术(包括诺亚的 Coverage 技术),以及使用了更大的训练数据集(据说数亿句对 vs. 一百万句对)。其实他们在方法上的创新并不多。可以说诺亚的基本技术与谷歌是持平的。
诺亚最近提出了三个方法,从不同角度提高深度机器翻译的精度。
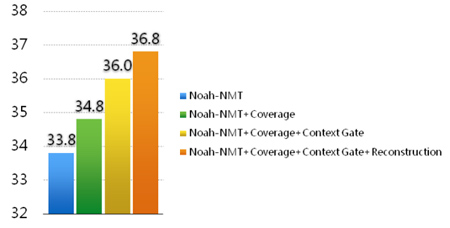
在 NIST 中英新闻翻译任务上,这三个方法将译文的 BLEU 分数从33.8逐步提高到36.8,取得了9%的提升,达到了业界领先水平。三个工作分别被自然语言处理和人工智能顶级会议及期刊 ACL 2016, TACL 2017 和 AAAI 2017 录用。第一个方法在业界得到广泛好评,也被谷歌采用。下图总结了诺亚的方法对深度翻译的提高。
1. 覆盖率(Coverage)机制 [11]:通过记录哪些词已经被翻译了,鼓励系统翻译未被翻译的词。这个方法可以显著减少遗漏翻译和过度翻译的错误数量。
2. 上下文门(Context Gate)方法[12]:在译文生成过程中,实词和虚词对原文信息的依赖是不一样的。该方法通过自动控制原文信息参与生成不同类型译文词的程度,使原文信息更有序、更完整地传输到译文中。
3. 基于重构(Reconstruction)的忠实度指标[13]:以译文重新翻译成原文的程度来衡量译文的忠实度。通过将重构指标引入训练过程,系统可生成更忠于原文的译文。
深度机器翻译并不能包打天下,在训练数据缺乏,以及人的知识加入的条件下,未必能够发挥威力。诺亚正在研究基于EAI思想的机器翻译,旨在将深度翻译与人的知识结合起来,以开发出更好的机器翻译系统。
下面介绍华为诺亚方舟实验室将 BLEU 分数提高到36.8%的基于重构的深度机器翻译方法[13],该论文被 AAAI 2017 录用。