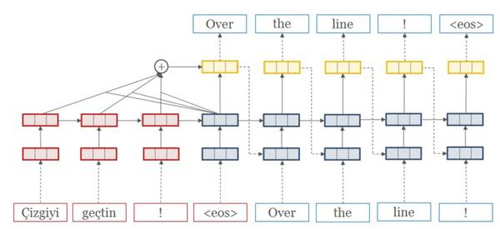
神经机器翻译是近段时间以来推动机器翻译发展的主要推动力。今天,哈佛大学自然语言处理研究组(Harvard NLP)宣布开源了其研发的神经机器翻译系统 OpenNMT,该系统使用了 Torch 数学工具包。该研究组在官网上表示该系统已经达到生产可用的水平(industrial-strength)。
官网:http://opennmt.net
代码:https://github.com/opennmt/opennmt
演示:https://demo-pnmt.systran.net
Docker 容器:https://hub.docker.com/r/harvardnlp/opennmt
OpenNMT 可以像主要的翻译服务提供商的已投入生产的系统那样使用。该系统简单易用,易于扩展,同时也能维持效率和当前最佳的翻译准确度。
其特性包括:
简单的通用型接口,仅需要源文件和目标文件;
为高性能 GPU 训练进行了速度和内存优化;
可以提升翻译性能的最新研究的特性;
有多个语言对的预训练好的模型(即将到来);
允许其它序列生成任务的扩展,比如归纳总结和图像到文本生成。
安装
OpenNMT 仅需要一次 vanilla torch/cutorch 安装。它要使用 nn、nngraph 和 cunn。有(CUDA)Docker 容器可选。
快速启动
OpenNMT 包含三条指令:
1)预处理数据
th preprocess.lua -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/demo
2)训练模型
th train.lua -data data/demo-train.t7 -save_model model